Overview of DLAB
The purpose of this page is to acquaint you with the DLAB project. The goal of the project is to:
Design, implement, and maintain a data lake for Ames National Laboratory’s unique data in order to facilitate data-driven scientific research.
So what is a data lake?
According to Microsoft a data lake is a “centralized repository that ingests and stores large volumes of data in its original form”. In turn, the data in the data lake constitutes the single source of truth, i.e., all other data in the data ecosystem should either reference the data in the data lake or be computed using the data in the data lake.
Training an AI/ML model is facilitated by having access to mass amounts of structured data, i.e., data with a fixed schema. Generally speaking, when data is generated it is NOT in a structured format, rather, it is unstructured data. Despite most AI/ML resources focusing on structured data, unstructured data is important because it is:
- the original source of truth,
- often costly/difficult to reproduce,
- usually describes how the data was created,
- usually contains sufficient information for converting the data to additional formats (necessary data may be lost during the wrangling process),
- often contains additional relationships/state not captured by initial data wrangling efforts.
The data lake is charged with collecting, organizing, and storing the raw unstructured data. With access to the unstructured data users can: reproduce results, repeat/modify previous analyses, and iteratively derive features for training AI/ML models.
How do we anticipate the data lake will be used?
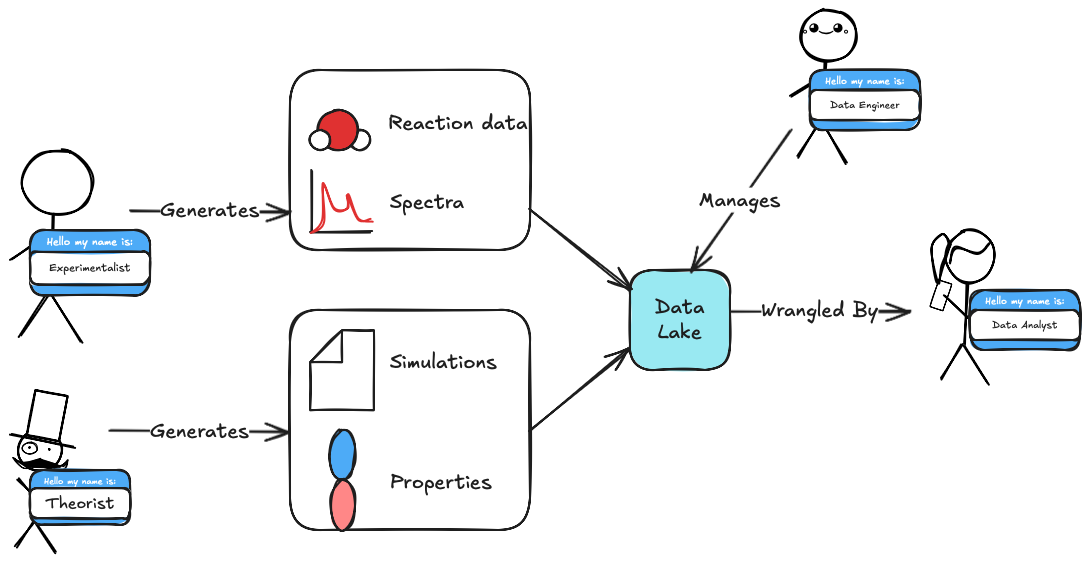
The above image provides a high-level overview of how we anticipate the data lake will be used. Scientists at the lab (both experimentalists and theorists) will continue to do amazing ground-breaking science. That science will generate data. The scientists will then deposit their data into the data lake. From the scientists’ perspective that’s it! This is then where the data engineers take over. The data engineers (via automations) are then responsible for making the new data discoverable, indexable, and available to users of the data lake. Finally, the data analysts are responsible (again via automations) for creating pipelines that transform unstructured data in the data lake into structured data.
We note that at Ames National Laboratory many of us wear multiple hats. So titles like “experimentalist” and “data engineer” should be viewed as different roles and not necessarily different people, i.e., there will certainly be some people interacting with the data lake in different capacities.